
Sampling random numbers from an image
Several times on my coding adventures with images I came into the need to sample random numbers form an image. For this I mean to get a random number that is more likely to land where the image is brighter and less likely were the image is darker. If you are familiar with the concept of probability distributions, what I want is to treat the image as the probability density function and sample from this.
The probability density function (or PDF for short) is a function that gives the likelihood of picking a particular point. You are probably familiar with the Gaussian distribution and it’s characteristic bell shape PDF.

There exist a number of methods for sampling form different distributions. Perhaps the must famous is the Inverse Transform Sampling strategy. However it won’t work on our case because it can only sample from one dimensional distributions whereas an image is of course a 2D function.
So to recap we need a method for sampling random numbers from a PDF defined by an image. For example we want to get more numbers around the letters on this image.

A method for sampling from an arbitrary distribution introduced in 1953 is the Metropolis–Hastings algorithm. This methods is a Markov chain Monte Carlo (MCMC) that generates a sequence of random numbers following the target distribution. This blog won’t get to much into the mathematical details of the method and will describe a simple implementation in p5.js.
Metropolis Algorithm#
The algorithm consists of two steps. First a new sample is proposed new value from a proposal distribution we already know how to sample from. A typical choice is the normal or gaussian distribution with a fixed standard deviation.
The second step is to accept or reject the proposed sample. First the ratio between the pdf at the prosed point and at the current value and call it $\alpha$.
$$ \alpha = \min\left(1, \frac{\text{pdf}(x_\text{proposed}, y_\text{proposed})} {\text{pdf}(x, y)}\right) $$
Remember that the pdf is the image we want to use. How to evaluate it as a function will be explained later. Then the proposed point is selected or rejected according to:
$$ x = \begin{cases} x_\text{proposed} & \text{if } u \leq \alpha \\ x & \text{otherwise} \end{cases} $$
with $u$ a random number from a uniform distribution between 0 and 1. Here are these steps in javascript:
function metropolis_step(x, y, sigma, target_pdf) {
let x_new = randomGaussian(x, sigma);
let y_new = randomGaussian(y, sigma);
let p = min(1, target_pdf(x_new, y_new) / target_pdf(x, y));
let u = random(1);
if (u <= p) return [[x_new, y_new], true];
else return [[x, y], false];
}
Building the sampler#
Now we can put it all in one function to generate a sequence of numbers
function metropolis_sample(x0, y0, sigma, target_pdf, n = 100, burnin = 100, lag = 3) {
let results = [];
// Burn-in
for (let i = 0; i < burnin; i++) {
[[x0, y0], accept] = metropolis_step(x0, y0, sigma, target_pdf);
}
// Sampling evrey lag steps
for (let i = 0; i < n; i++) {
for (let j = 0; j < lag; j++) {
[[x0, y0], accept] = metropolis_step(x0, y0, sigma, target_pdf);
}
results.push([x0, y0]);
if (accept) results.push([x0, y0]);
else i -= 1;
}
return results;
}
This methods first generates samples for a burn in period to make sure the
sequence has converged before starting the saving the points. Also the sequence
gets generated only every lag iterations to avoid autocorrelation between the
samples, a known problem of MCMC methods.
How to evaluate the pdf#
The algorithm requires that to evaluate the pdf at arbitrary points but we are using an image which you can not really evaluate. Images are represented as arrays that have to be evaluated at discrete points. To solve this one can use interpolation. Here is the most simple case of nearest neighbors interpolation.
function nearest_neighbors(x, y, arr) {
return arr[floor(max(min(x, width-1), 0))][floor(max(min(y, height-1), 0))];
}
Conclusions#
Putting it all together we can draw points from the image shown above.
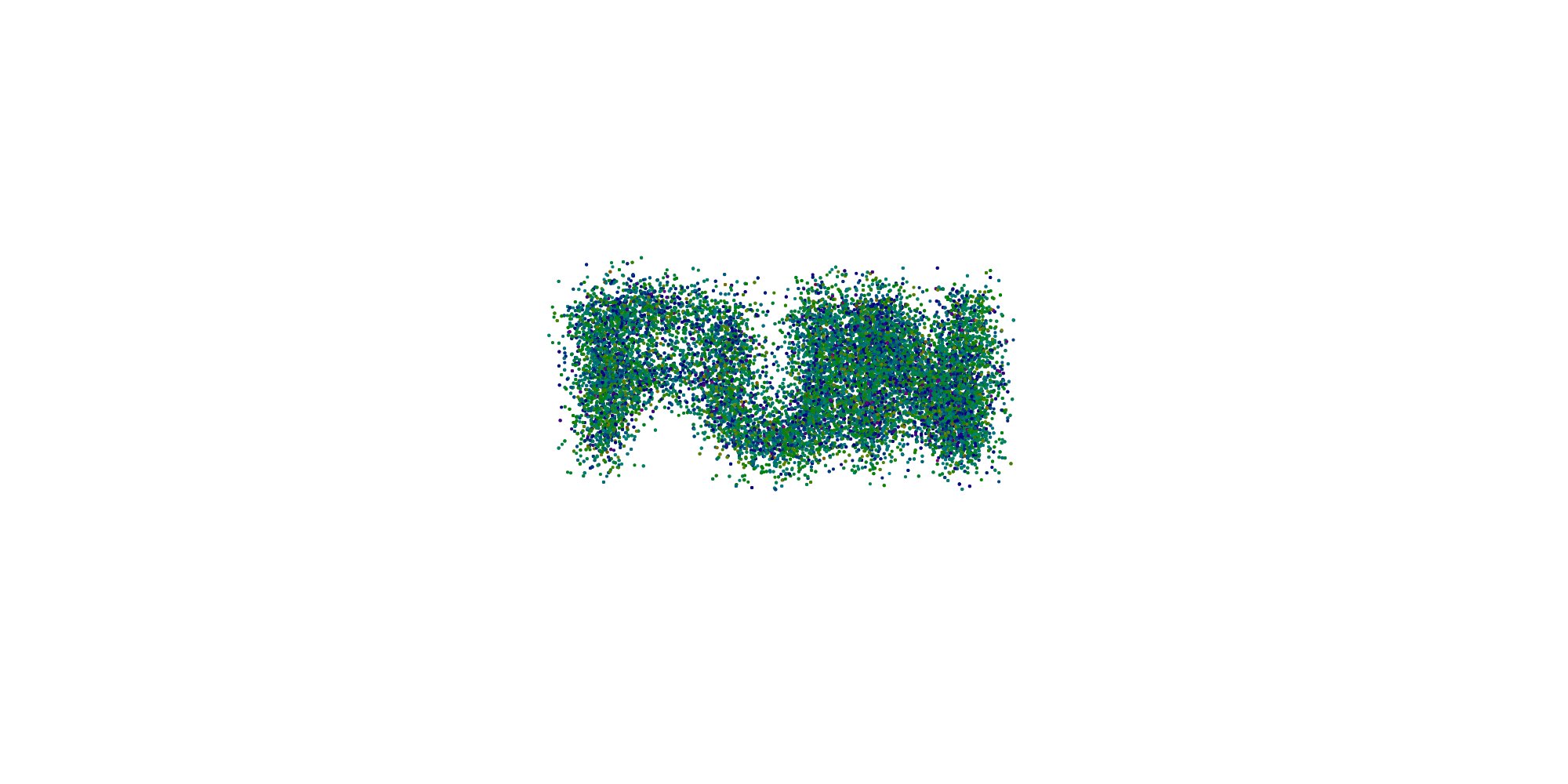
You can have a look at the whole application here
Notes#
There is no need to to normalize the pdf because only it’s ratio is important and thus the normalizing constant cancels out.
This implementation is not particularly efficient for real time use.
Links#
- The Metropolis-Hastings algorithm by Danielle Navarro
- The Metropolis–Hastings algorithm by C.P. Robert