
AI puede crear obras de arte - Style Transfer en Keras
En un post anterior exploramos los filtros de una red convolucional (CNN) para entender como esta funcionaba. Esa ves buscamos una imagen que maximice la activacion en cada filtro y de esta forma veíamos las características que este estaba detectando. Al final del articulo mencionamos el trabajo realizado en Google para crear imágenes de ensueño conocido como DeepDream. Poco después de la publicación de DeepDream, Gatys et al. [1] mostraron como aplicar la técnica para generar obras de arte a partir de una foto siguiendo el estilo de una obra.
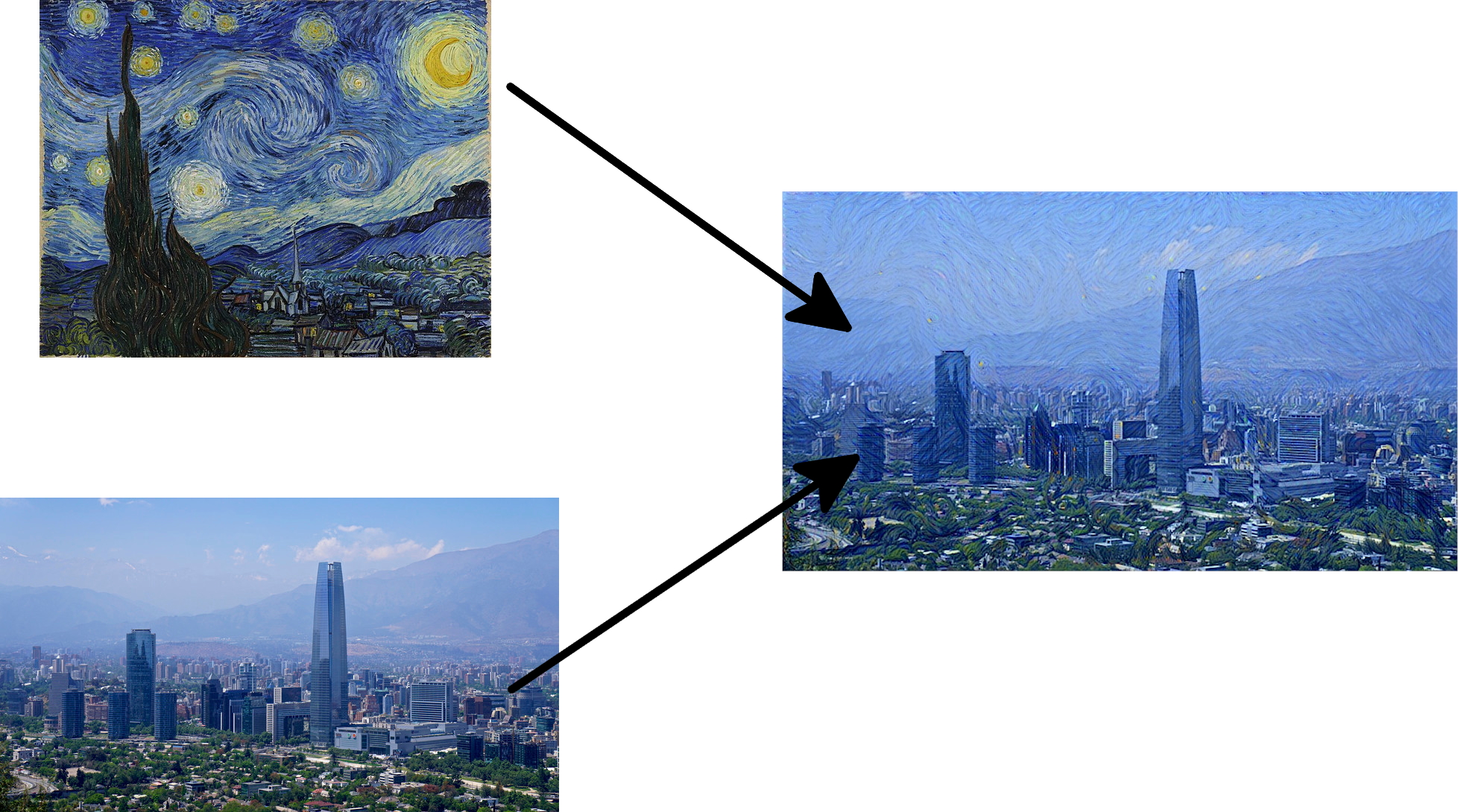
Style transfer#
Los autores plantearon el problema de transferir el estilo de una imagen a otra como un problema de optimización. Intuitivamente las características de una foto se pueden dividir entre el contenido y el estilo (o texturas). El contenido corresponde a la información sobre la forma y ubicación de los objetos de la foto. El estilo son las texturas y patrones de la imagen. Bajo esta perspectiva si generamos una imagen con el contenido de una foto pero con las texturas de una obra de arte podemos “traspasar” el estilo del artista a la foto.
Para extraer el contenido y estilo de las imágenes los autores plantean el uso de una red CNN pre entrenada (especificamente la red VGG19 entrenada en ImageNet). Las CNNs entrenadas para clasificar sobre un gran volumen de datos aprenden una gran cantidad de filtros con distintas características que permiten identificar los objetos presentes. En cada etapa de la red la cantidad de filtros aumenta y el tamaño de las imágenes se disminuyen produciendo una reducción en la cantidad de unidades por capa. La representación contenida en estos filtros se puede utilizar para reconstruir la imagen original (abajo en la figura) o para reconstruir construir un espacio que considere solo la textura y estilo de una imagen (arriba en la figura).
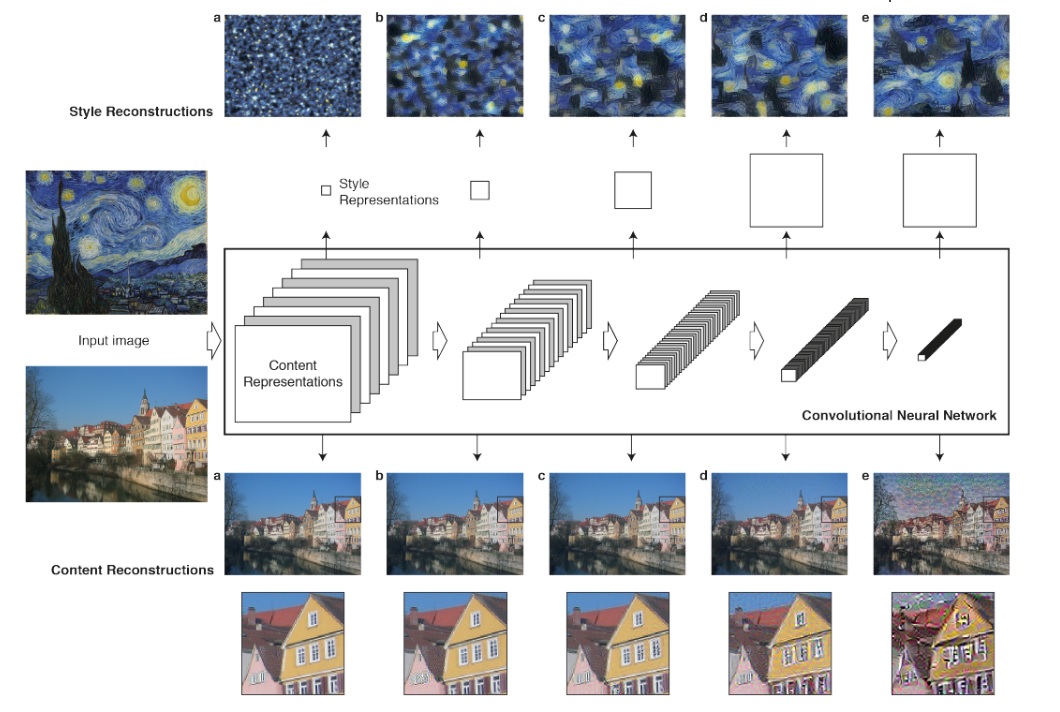
La imagen solución es una que minimize simultáneamente la diferencia en estilo con la obra de arte y el contenido con la fotografiá. Denotando $x$ la imagen objetivo, $x_s$ la foto original y $a_t$ la obra de arte, la función de perdida a minimizar es,
$$\min_x \mathcal{L}=\frac{1}{2}(C(x)-C(x_s))^2-\lambda\frac{1}{2}(S(x_s)-S(a_t))^2$$
La expresión $(C(x)-C(x_s))^2$ es la diferencia en el contenido y el termino $(S(x_s)-S(a_t))^2$ es la diferencia en estilo. El valor de $\lambda$ es una constante para indicar una preferencia por el estilo o el contenido en la solución.
Implementación en Keras#
Primero cargamos las imágenes y el modelo VGG19 pre entrenado directamente de Keras.
from keras.applications import vgg19
from PIL import Image
import requests
import numpy as np
import matplotlib.pyplot as plt
model = vgg19.VGG19(weights='imagenet', include_top=False)
print('Model loaded.')
# model.summary()
van_gogh_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/e/ea/Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg/606px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg"
santiago_url = "https://upload.wikimedia.org/wikipedia/commons/7/7e/Stog_skyline_wikipedai.jpg"
van_gogh = np.array(Image.open(requests.get(van_gogh_url, stream=True).raw).convert("RGB"))
santiago = np.array(Image.open(requests.get(santiago_url, stream=True).raw).convert("RGB"))
El estilo de la obra de arte y el contenido de la foto no va a cambiar durante el entrenamiento asi que es conveniente calcularlo previamente y guardarlo en una variable. Para obtener el resultado de una capa intermedia usamos un modelo donde la salida sea esa capa y predecimos las imágenes en el.
from keras.models import Model
photo = vgg19.preprocess_input(np.array([santiago]))
target = vgg19.preprocess_input(np.array([van_gogh]))
target_style = []
target_content = Model(inputs=model.input, outputs=model.get_layer("block1_conv1").output).predict(photo)
target_style.append(Model(inputs=model.input, outputs=model.get_layer("block5_conv1").output).predict(target))
target_style.append(Model(inputs=model.input, outputs=model.get_layer("block4_conv1").output).predict(target))
target_style.append(Model(inputs=model.input, outputs=model.get_layer("block3_conv1").output).predict(target))
target_style.append(Model(inputs=model.input, outputs=model.get_layer("block2_conv1").output).predict(target))
Yo elegí estas capas porque parecen dar buenos resultados esta situacion pero deberias experimentar con otras combinaciones.
Ahora definimos una función de Keras para calcular la función de perdida y el gradiente respecto de la imagen generada. Primero calculamos la perdida respecto del contenido
from keras import backend as K
content = model.get_layer("block1_conv1").output
content_loss = 0.5*K.sum(K.pow(content - target_content, 2))
Para calcular el error respecto del estilo debemos eliminar las relaciones espaciales implícitas en los filtros. La solución propuesta por Gatys et al. [1] es usar la matriz de Gram. Definida como la matriz formada por el producto punto entre todos los vectores pertenecientes al conjunto. La forma mas simple de implementarlo es como la multiplicación $AA^T$ para una matriz $A$ cuyas filas sean los vectores requeridos. Adicionalmente el estilo es escala por la cantidad de elementos en la imagen.
def gram_matrix(x):
# print(x.shape)
x = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
return K.dot(x, K.transpose(x))
style = []
style.append(model.get_layer("block5_conv1").output)
style.append(layer_dict["block4_conv1"].output)
style.append(layer_dict["block3_conv1"].output)
style.append(layer_dict["block2_conv1"].output)
def get_style_loss(x, y, w):
size = x.shape[1] * x.shape[2] * y.shape[1] * y.shape[2]
target_gram = gram_matrix(y[0])
photo_gram = gram_matrix(x[0])
loss = 0.25*K.sum(K.pow(target_gram - photo_gram, 2))
loss = w*loss /(3*422*750)**2
return loss
style_loss = [get_style_loss(s, ts, 1) for (s, ts) in zip(style, target_style)]
# cambiar a la version final
lam = 1e2
loss = content_loss
for i, s, ts in enumerate(style_loss, zip(style, target_style)]):
w = 1/(i+2)
style_loss = get_style_loss(s, ts, w)
loss += lam*style_loss
Luego la perdida total queda
lam = 1e2
loss = content_loss + lam*style_loss
Usando la misma técnica que en el articulo anterior, creamos una función para calcular la perdida y el gradiente
input_img = model.inputs[0]
grads = K.gradients(loss, input_img)[0]
# es importante normalizar los gradientes
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
# una funcion para calcular la los gradientes dada una imagen de entrada
iterate = K.function([input_img], [loss, grads])
Ya estamos llegando al final. Lo único que falta es iterar sobre la rutina que acabamos de definir actualizando la imagen en cada paso partiendo de ruido blanco.
def deprocess_image(x):
# sumar la media para volver al rango original
mean = [103.939, 116.779, 123.68]
x = x[..., ::-1]
x[..., 0] += mean[0]
x[..., 1] += mean[1]
x[..., 2] += mean[2]
return np.clip(x, 0, 255)
input_img_data = np.random.random(photo.shape)
# partimos de una imagen de ruido blanco
import time
# iteramos
start_time = time.time()
step = 0.01 # cuanto actualizamos la imagen cada ves (learning rate)
for i in range(1500):
loss_value, grads_value = iterate([input_img_data])
input_img_data -= grads_value * step
if i % 100 == 0:
print(i, loss_value)
total_time = time.time() - start_time
final = deprocess_image(input_img_data[0, ...])/255
print("{:02d}:{:.2f}".format(round(total_time//60), total_time % 60))
im = Image.fromarray((final*255).astype('uint8'))
im.save("/content/result.jpg")
Después de aproximadamente 10 minutos en una GPU este es el resultado

Nada mal para solo unas 100 lineas de código. Ahora tu también puedes usar esta técnica para convertir tus fotos en obras de arte. Prueba modificando los parámetros del algoritmo. ¿Como se comporta si $\lambda$ disminuye? ¿Qué pasa si usas otras capas para calcular el estilo?.
Como vimos en este articulo las características aprendidas por redes de CNN son capaces de generalizarse para tareas de generación. Lo aprendido parce tener información util no solo para clasificar sino que capturan información de alto nivel semántico de la entrada. Esta area creo vale la pena explorar mas en profundidad.
Puedes descargar el código de aquí. Otras mejoras mas avanzadas podría ser usar un mejor algoritmo de optimización (agregar momentum o usar L-BFGS). También puedes experimentar agregar un regularizador como TV (total variation) a la función de perdida para eliminar el ruido y estimular la suavidad en la solución.